![]()
작성일: 2015.10.30
차세대 시스템 요건을 충족시켜줄 새로운 FPGA 아키텍처와 최첨단 FinFET 공정 기술...
![]()
2015.07.07 by 편집부
본 백서에서는 차세대 시스템의 성능 요건들을 기존의 FPGA로 충족시키려 할 때 직면하게 되는 문제점들을 살펴보고, HyperFlex™
아키텍처로 알려진 알테라의 새로운 코어 아키텍처를 소개한다. 이 새로운 HyperFlex 아키텍처와 알테라만이 독점적으로 사용 가능한 인텔의
14nm Tri-Gate 공정기술은 Stratix® 10 FPGA와 SoC로 이전 세대의 고성능 FPGA에서는 상상도 못했던 수준의 성능과 전력
효율성을 구현할 수 있도록 해준다. 이 디바이스들이 구현하는 특징들은 다음과 같다
- 이전 세대의 Stratix V FPGA보다 배가된 코어 성능과 5배 이상 높아진 집적도
- 동일한 성능일 경우 Stratix V FPGA보다 최대 70퍼센트 적어진 소비 전력
- 1 GHz 속도로 동작 가능한 로직, 내장 메모리 및 DSP 블록
- 내장된 콰드코어 64비트 ARM® Cortex®-A53 하드 프로세서 시스템(SoC 버전)
- 입증된 Quartus® II 소프트웨어의 지원을 받는 익숙한 FPGA 설계 기법들
업계의 해결과제
모든 주요 산업 분야의 전자 시스템 개발자들은 자신들이 지난 수십 년간 구현해온 맹렬한 속도 증가 추세를 지속시키지 않으면 안 되는
상황에 직면하고 있다. 군사통신 및 컴퓨터 스토리지 환경과 같이 다양한 시장의 고객들은 보다 빠른 시스템을 원할 뿐만 아니라 크기가 보다 작고
전기 소비도 보다 적은 시스템을 원하고 있다.
하지만 속도에 대한 요구는 새로울 것이 없다. 달라지고 있는 것은 유무선, 군사, 방송, 컴퓨팅 및 스토리지 분야의 요구가 한층 더
까다로워지고 있다는 점이다. 많은 분야에서 이러한 요구들은 마치 호황 때를 방불케 하는 두 자릿수의 높은 증가율을 보이고 있다.
![[그림 1]](img_20150707183413.png)
[그림 1] 유선, 무선, 데이터센터와 같은 애플리케이션 분야의 고객 요구가 증가하고 있다
정보통신 기술 부문은 고객의 요구가 이들을 지원하는 시스템 개발자와 반도체 공급업체들의 역량에 도전하고 있는 대표적인 분야이다. 엄청난
양의 데이터가 전세계 네트워크를 누비는 추세로 인해 전세계의 대역폭 소비 규모는 매 2~3년마다 배가하고 있다. 2016년에는 이제까지 제작된
모든 영화들을 합친 양에 해당하는 데이터가 매 3분마다 이 네트워크들을 통해 사방으로 전송될 것이다. 시장조사업체인
텔레그래피(TeleGeography)사(1)는 인터넷 대역폭이 2010년~2012년 기간에 배 이상 증가한 초당 77 테라비트로 치솟았다고 밝혔다.
자동차로부터 산업 장비는 물론 냉장고와 같은 가전 제품에 이르기까지 모든 것들이 인터넷에 연결됨에 따라 통신 능력에 대한 요구는 치솟게
될 것이다. 가트너는 2009년에 9억 개였던 사물인터넷(IoT) 수가 2020년에는 거의 30배 이상 증가한 260억 개에 이를 것이라 예상하고 있다.(2)
많은 동향들이 이 같은 끝없는 대역폭 증가에 기여하고 있다. 예를 들어, 초당 100 기가비트(Gbps) 속도의 이더넷이 현재 널리
사용되고 있는 40 Gbps 버전을 이제 막 대체하기 시작했지만, IEEE는 이미 400 Gbps 표준을 추구하기 위한 전담부서를 최근 설립한 바 있다.(3)
아직은 유선 네트워크가 가장 많은 데이터를 전송하고 있지만, 무선 시장이 이러한 추세를 역전시키려 하고 있다. Cisco사의 보고서에
따르면, 2011년에는 유선 장치가 IP 트래픽의 55 퍼센트 가까이를 차지했었다. 그러나 스마트 모바일 장치의 폭발적인 성장을 보건대,
머지않아 무선 장치가 트래픽의 주류를 이룰 것임을 어렵지 않게 예상할 수 있다. Cisco사는 모바일 데이터 트래픽 규모가 2013년의 1.6
엑사바이트로부터 2017년에는 11.2 엑사바이트로 치솟을 것이라 예상하고 있다.(4)
다른 분야들도 두 자리수의 엄청난 성장률을 보이고 있어 보다 빠른 데이터 처리 장비에 대한 필요성은 더욱 커지고 있다. 위성통신은 아직
군사용이 주를 이루고 있지만, 이 역시 드론과 위성이 더욱 많은 데이터를 생성하고 과거보다 훨씬 더 많은 사람들이 이를 사용함에 따라 트래픽이
치솟고 있다. 이로 인해 지상 백홀 스테이션(backhaul station)의 요건이 급상승하고 있다.
Northern Sky Research(NSR)사는 위성 백홀 사이트의 전세계 설치 기반이 2012년~2022년 기간에 50퍼센트 이상
증가할 것으로 예상하고 있다.(5) 이동통신 사업자 고객들의 3G/4G/LTS 백홀 요건들을 비용효율적으로 충족시켜야 할 필요성이 이러한 증가
추세를 이끌고 있다. NSR사는 고전송률 위성(high throughput satellite, HTS)의 총 전송용량에 대한 요구가
2022년경에는 백홀 서비스 한 분야만도 133.5Gbps나 증가할 것으로 예측하고 있다. NSR사의 전망에 따르면, 전세계 위성 광대역 액세스
시장에서는 향후 10년 동안에 신규 가입자 수가 430만 명 이상 추가될 것이며, 북미 지역의 경우에는 2022년 경에 240만 명 가까운 신규
가입자가 추가될 것이라고 한다.
지상에서는 이동통신 부문이 보다 빠른 칩과 시스템에 대한 요구를 견인하고 있다. Cisco사의 전망에 따르면, 2011년~2016년
기간에 모바일 트래픽 규모는 78퍼센트 증가할 것으로 예상된다고 한다. 이 중 상당부분은 비디오에 의한 것으로서, 2011년~2016년 기간에
연간 90퍼센트의 성장률을 보이게 될 것이다. Cisco사는 2016년 경에는 모바일 비디오가 전체 모바일 데이터 트래픽의 70퍼센트 이상을
차지하게 될 것으로 예상하고 있다.(6)
비디오에 대한 대중의 요구는 방송 산업 분야의 강력한 성장도 촉발시키고 있다. 2019년경에는 대부분의 국가들이 디지털 TV로의 전환을
마칠 것으로 예상된다. 또한 HDTV의 성장과 초고해상도(UHD) 기술의 출현으로 인해 보다 빠른 편집 및 전송 시스템에 대한 필요성이 대두될
것으로 예상된다.
소비전력과 발열의 감소
이 모든 분야에서 이제는 단지 보다 빠른 장비를 설계하는 것만으로는 더 이상 충분치 못하게 되었다. 전력소비는 환경 문제에 대한 우려
뿐만 아니라 절전에 따르는 비용절감 때문에 중요한 문제가 되었다. 칩 제조업체와 시스템 개발자 모두에게 있어서 절전은 대부분의 프로젝트에서
중심요소가 되었다. 시스템 설계 팀들에게는 절전에 따른 발열 감소도 반가운 부분인데, 이는 방열 문제에 들이는 시간을 줄일 수 있기
때문이다.
데이터센터는 절전과 발열감소가 요구되는 전형적인 예라고 할 수 있다. 데이터센터 다이내믹스(Datacenter Dynamics)의
2012년도 글로벌 센서스에 따르면, 2011년~2012년 기간에 전세계 데이터센터의 전력 요구량은 2011년의 24 기가와트(GW)로부터
2012년에는 38 기가와트로 상승하여 63퍼센트의 증가율을 보였다고 한다.(7) 미국의 많은 통계학자들은 조나단 쿠미 박사의 연구결과를
인용하여 데이터센터가 미국 내 전기 사용량의 2퍼센트 정도를 소비하고 있는 것으로 보고 있다.(8)
새로운 접근 방법의 필요성
어떤 업계인가에 관계 없이, 차세대 시스템들은 갈수록 더 큰 데이터 처리량과 보다 높은 클럭 주파수 성능을 필요로 하고 있다. 이러한
현실과 신제품을 신속하게 출시해야 할 필요성에 직면한 수많은 기업들이 현재 FPGA를 자사 시스템 디자인의 핵심 구성요소로서 사용하고 있다.
이들 FPGA의 데이터 처리량은 전반적인 시스템 성능을 결정하는 데 있어서 극히 중요한 요소일 때가 많다.
FPGA의 데이터 처리량을 개선하기 위해 가장 흔히 사용되는 기법은 온칩 버스의 폭을 점점 더 넓히는 것이다. FPGA에서는 512
비트나 1,024 비트, 심지어는 그보다 더 넓은 버스를 사용하는 일도 흔하다. 이처럼 폭 넓은 버스를 사용하기 위해서는 비용이 많이 드는
FPGA 자원을 이용해야 하며 전력소모도 커진다. 게다가 버스의 모든 비트에 걸쳐 비교기나 체크섬과 같은 고속 로직 기능들을 수행하기가
어려워진다.
보다 폭넓은 버스를 사용하는 것 외에도 시스템 개발자들은 데이터 경로의 대대적인 파이프라인화를 통해 클럭 주파수를 높인다. 그러나 폭이
넓은 버스를 파이프라인화 하기 위해서는 버스의 각 비트마다 FPGA 자원을 추가로 소비해야 하는데, 이 또한 비용이 많이 드는 일이다. 따라서
버스 폭을 갈수록 더 넓게 만든다는 것은 실용적이 못 된다.
차세대 기술 노드로 옮겨가는 것도 성능 향상을 가져온다. 그러나 공정 지오메트리가 계속 축소됨에 따라 로직 블록들 간의 인터커넥트
지연이 FPGA의 총 지연에서 차지하는 비중은 점점 더 커지고 있다. 기존의 FPGA 아키텍처를 차세대 기술 노드로 진전시킨다 해도 이 문제는
해결되지 않는다. 이처럼 그 중요성이 점점 더 커지고 있는 인터커넥트 지연 문제를 해결하기 위해서는 보다 나은 솔루션이 필요하다.
상상을 뛰어넘는 성능 구현
Stratix 10 디바이스의 새로운 HyperFlex 아키텍처는 이러한 문제들을 해결하기 위한 혁신적인 접근방법이다. 이 아키텍처는
기존의 FPGA 아키텍처로는 도저히 실현할 수 없는 성능과 전력 효율성을 제공한다. 새로운 HyperFlex 아키텍처를 인텔의 14nm
Tri-Gate 공정 기술과 함께 사용함으로써 개발자들은 Stratix 10 FPGA와 SoC의 코어 성능을 이전 세대의 고성능 FPGA에 비해
배가시킬 수 있다.
HyperFlex의 이점
HyperFlex의 이점을 가능케 해주는 주요 혁신사항들은 다음과 같다
모든 곳에 편재하는 레지스터
 인터커넥트 배선의 “모든 곳에 편재하는 레지스터(registers everywhere)”를 하이퍼 레지스터(Hyper-Register)라고
하며, 이는 적응형 로직 모듈(ALM: adaptive logic module) 내에 포함되어 있는 기존의 레지스터들과는 뚜렷하게 구별된다.
인터커넥트 배선의 “모든 곳에 편재하는 레지스터(registers everywhere)”를 하이퍼 레지스터(Hyper-Register)라고
하며, 이는 적응형 로직 모듈(ALM: adaptive logic module) 내에 포함되어 있는 기존의 레지스터들과는 뚜렷하게 구별된다. 하이퍼 레지스터는 디바이스 내의 각 개별 배선 부분과 관련이 있으며, ALM,
임베디드 메모리(M20K) 블록 및 DSP(digital signal processing)와 같은 모든 기능 블록들의 입력부에도 제공된다.
하이퍼 레지스터는 우회할 수 있으므로 설계 툴들은 배치 및 배선 작업 후에 최적의 레지스터 위치를 자동적으로 선택함으로써 코어 성능을
극대화할 수 있다.
인터커넥트 전체에 하이퍼 레지스터를 탑재하면 (기존의 아키텍처와는 달리) 성능 조정을 위해 ALM 자원이 추가로 필요하지 않으며,
디자인의 배치 및 배선을 추가로 변경할 필요도 없고 복잡성이 증가하지도 않는다. 그 밖에도 하이퍼 레지스터를 인터커넥트에 내장하면 배선이
혼잡해지는 것을 줄이는 데도 도움이 된다.
향상된 코어 클러킹
 프로그래머블 클럭 트리 합성 기능은 시스템 개발자들이 로컬화된 클럭 트리를 생성하여 스큐와 타이밍 불확실성을 줄임으로써 코어 클러킹 성능을 극대화할 수 있도록 해준다. 이러한 능력은
HyperFlex 아키텍처가 성능을 배가시킬 수 있도록 해주는 주요 특징 중 하나이다. 이 밖에도 코어 클러킹은 지능형 브랜치 활성화 기능을
이용하여 클럭 네트워크의 동적 전력 소비를 줄여준다.
프로그래머블 클럭 트리 합성 기능은 시스템 개발자들이 로컬화된 클럭 트리를 생성하여 스큐와 타이밍 불확실성을 줄임으로써 코어 클러킹 성능을 극대화할 수 있도록 해준다. 이러한 능력은
HyperFlex 아키텍처가 성능을 배가시킬 수 있도록 해주는 주요 특징 중 하나이다. 이 밖에도 코어 클러킹은 지능형 브랜치 활성화 기능을
이용하여 클럭 네트워크의 동적 전력 소비를 줄여준다.하이퍼 어웨어 설계 흐름
- 성능을 모색해볼 수 있도록 해주고 사용자가 설계 성능을 극대화 할 수 있도록 이끌어 주는 패스트 포워드 컴파일(Fast Forward Compile) 툴.
- 배치 및 배선 작업 후의 성능 최적화를 지원해 주는 하이퍼 리타이머(HyperRetimer) 단계.
- 하이퍼 레지스터를 이용하는 향상된 합성과 배치 및 배선 알고리즘.
고성능 그 이상의 이점들
HyperFlex 아키텍처의 향상된 코어 성능은 시스템 개발자에게 여러 가지 이점들을 제공하는데, 이러한 이점들은 다음 사항에서 보듯이
단지 코어를 보다 빠르게 실행할 수 있다는 명백한 이점에서 그치지 않는다
- 보다 향상된 코어 성능 덕분에 타이밍 클로저를 보다 손쉽고 빠르게 수행할 수 있으므로 설계 팀의 생산성이 향상되고 제품의 타임투마켓이 단축된다.
- 보다 향상된 코어 성능은 개발자들이 보다 저속 등급의 디바이스를 사용하면서도 성능 요건을 능가함으로써 솔루션 비용을 절감할 수 있도록 해준다.
- 디자인을 배가된 속도로 실행할 수 있는 보다 향상된 코어 성능을 원래의 내부 버스폭의 절반으로 구현함으로써 디자인의 전체 크기를 축소시킬 수 있다. 따라서 디자인을 훨씬 더 작은 디바이스에 집어넣을 수 있으므로 솔루션 비용이 절감된다.
인텔 어드밴티지
2013년 2월에 알테라는 인텔의 14nm Tri-Gate(FinFET) 공정 기술이 차세대 Stratix 10 FPGA 및 SoC의
제조에 사용될 것이라고 발표했다. 이 기술은 획기적인 수준의 집적도, 성능 및 전력 효율성을 제공한다. 이 기술의 기반이 되는 3D
FinFET(Tri-Gate) 트랜지스터는 공정 지오메트리가 20nm 이하로 축소됨에 따라 기존의 2D 평면 MOSFET 트랜지스터를 대체하고
있다. 이미 모든 주요 실리콘 파운드리들이 3D FinFET 트랜지스터로 전환할 계획임을 발표했다. 알테라와 그 고객사들은 인텔을 Stratix
10 디바이스를 위한 파운드리 파트너로 선택함으로써 “인텔 어드밴티지(The Intel Advantage)”가 제공하는 수많은 이점들을 누릴 수
있게 되었다. 이러한 이점들 때문에 인텔의 14nm Tri-Gate 기술은 새로운 HyperFlex 아키텍처를 구현하기에 이상적인 공정이다.
알테라와 그 고객사들이 인텔과의 유대 관계를 통해 얻을 수 있는 최고의 이점 다섯 가지는 다음과 같다
- 독점권 : 알테라는 주요 FPGA 벤더들 중에 유일하게 인텔의 14nm Tri-Gate 기술을 액세스할 수 있는 업체이다. 이러한 독점권은 알테라와 인텔 간의 강력한 유대관계를 잘 보여주고 있다. 알테라의 고객사들만이 업계를 선도하는 인텔의 공정 기술을 이용할 수 있다.
- 생산 능력 : 다른 주요 반도체 파운드리들도 FinFET 트랜지스터 기반의 새로운 공정 개발 계획을 발표했다. 그러나 FinFET 기술을 연구소 레벨이 아닌 생산 현장에 구현하기 위해서는 가파른 학습곡선을 거쳐야 한다. 아직까지는 생산 단계로 전환한 업체는 인텔 뿐으로서, 이미 5억 개 이상의 FinFET 트랜지스터 디바이스를 출하했다.
- 한 단계 앞서가는 공정 : 인텔이 22nm의 Tri-Gate 공정을 선보인 지도 이미 3년이 넘었다. 이 기술은 현재 14 nm까지 발전하였으며, 알테라의 Stratix 10 FPGA 및 SoC에 사용되고 있다. 다른 반도체 파운드리들이 개발 중인 FinFET 공정들은 기존의 20nm 디자인 룰을 이용하여 시작될 것이다. 이들은 인텔과 동일한 수준으로 축소된 공정을 채택하고 있지 못하므로 사실상 한 공정 앞서 있는 인텔이 성능, 전력 효율성 및 집적도 면에서 커다란 이점을 가지고 있다.
- 성숙도 : 인텔과 알테라는 2세대의 14nm Tri-Gate 기술을 이용하고 있다. 반면에, 다른 파운드리 중에는 언제 1세대 FinFET 공정으로 칩 제작에 착수할 계획인지 공표한 곳이 한 곳도 없다. Stratix 10 FPGA 및 SoC는 성숙 단계에 들어선 인텔 14nm Tri-Gate 공정 기술의 이점을 누리고 있다
- 설계 전문기술 : 인텔은 FinFET 트랜지스터를 이용하여 고속의 로직, 아날로그, 디지털 및 혼성신호 회로들을 설계 및 생산할 수 있는 능력을 보유하고 있음을 입증해 보인 바 있다. 알테라는 이처럼 풍부한 설계 전문기술을 이용할 수 있으므로 Stratix 10 FPGA 및 SoC가 인텔의 14nm Tri-Gate 공정 기술 능력을 최대한 활용하도록 할 수 있다.
알테라는 또한 인텔과의 유대 관계를 통해 유일하게 미국에서 생산되는 주요 고성능 FPGA 및 SoC 제품들을 제공할 수 있다. 이를
통해 세계 수준의 패키지 및 어셈블리 능력을 이용할 수 있으며, 14nm Stratix 10 FPGA 및 SoC와 다른 첨단 부품들(SRAM,
DRAM, ASIC, 프로세서 및 아날로그 부품들을 포함할 수 있다)을 단일 패키지에 통합시킨 이종 멀티 다이 디바이스들을 개발할 수 있다.
이러한 이점들이 알테라의 Stratix 10 FPGA 및 SoC 고객들에게만 제공되는 “인텔 어드밴티지”이다.
HyperFlex 아키텍처
새로운 HyperFlex 아키텍처의 중심부는 혁신적인 “모든 곳에 편재하는 레지스터” 디자인으로서, 우회 가능한 하이퍼 레지스터들이
FPGA 코어 내의 모든 배선 부분과 모든 기능 블록 입력부에 추가되어 있다. 그림 2는 우회 가능한 하이퍼 레지스터로서, 배선 신호는
레지스터를 우회하여 바로 멀티플렉서로 가거나 혹은 레지스터를 먼저 통과할 수도 있다. 멀티플렉서는 FPGA 구성 메모리(CRAM)의 1 비트에
의해 제어된다.
![[그림 2]](img_20150707184854.png)
[그림 2] 우회 가능한 하이퍼 레지스터
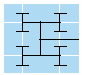
그림 3은 FPGA 패브릭의 작은 일부분으로서, 9개의 ALM과 이들을 연결시키는 인터커넥트 배선으로 구성되어 있다. 하이퍼 레지스터의
위치는 각 수평 및 수직 배선 부분의 교차 지점에 있는 정사각형으로 표시된다.
![[그림 3]](img_20150707184906.png)
[그림 3] "모든 곳에 편재하는 레지스터” 디자인의 HyperFlex 아키텍처
HyperFlex 아키텍처를 이용해 디자인의 성능을 극대화하기 위해 개발자들은 익숙한 설계 기법들을 기반으로 하는 레지스터
리타이밍(register retiming), 파이프라이닝(pipelining) 및 설계 최적화(design optimization)의 3단계
프로세스를 이용한다. 하이퍼 레지스터는 개발자들이 익숙한 설계 기법들을 이용하여 디자인 성능을 기존의 FPGA 아키텍처에서 가능했던 것보다
비약적으로 향상시킬 수 있도록 해준다. 이처럼 일반적인 기법들을 ALM 내의 레지스터 대신에 하이퍼 레지스터를 이용하여 구현할 경우, 이
기법들의 이름은 하이퍼 리타이밍(Hyper-Retiming), 하이퍼 파이프라이닝(Hyper-Pipelining) 및 하이퍼
옵티마이제이션(Hyper-Optimization)으로 바뀐다. 표 1에는 각 단계에서 이루지는 성능 향상이 요약되어 있다.
![[표 1]](img_20150707191532.png)
[표 1] HyperFlex 아키텍처를 이용하여 성능을 극대화하기 위한 3단계 프로세스
공정 지오메트리가 축소됨에 따라 ALM들 간의 인터커넥트 지연이 지배적인 영향력을 미치면서 성능을 제한하고 있다. 이 문제를 가장 잘
다룰 수 있는 인터커넥트 배선 부분에 하이퍼 레지스터를 두는 것이 HyperFlex 아키텍처의 주요 핵심사항 중 하나이다.
하이퍼 리타이밍
디자인의 리타이밍은 인터커넥트 배선에 있는 하이퍼 레지스터를 이용하여 이루어진다. 이 프로세스는 사용자의 노력이 거의 또는 전혀 들지
않으면서도 Stratix 10 디바이스의 경우 이전 세대의 고성능 FPGA에 비해 평균 1.4배의 성능 향상을 가져온다. 하이퍼 리타이밍은
레지스터를 ALM으로부터 인터커넥트로 옮기고 레지스터 간의 지연을 균형 있게 조절하며 디자인이 보다 빠른 클럭 주파수로 실행될 수 있도록
함으로써 임계 경로들을 제거한다. 하이퍼 레지스터가 인터커넥트 전반에 걸쳐 존재하므로 레지스터의 위치는 미세 단위로 분포된다. 기존의
리타이밍에서는 FPGA의 로직 및 배선 자원이 추가로 필요하며, 디자인을 재컴파일, 재피팅 및 재배선 해야 한다. 이와는 대조적으로, 하이퍼
리타이밍은 FPGA 자원을 추가로 사용하지 않으며, 배치 및 배선 작업 후에 수행되므로 개발자의 노력을 거의 또는 전혀 들이지 않고도 코어
성능을 크게 향상시킬 수 있다.
하이퍼 파이프라이닝
디자인의 파이프라이닝 및 리타이밍은 하이퍼 레지스터를 이용하여 이루어진다. 이 기법은 사용자의 노력이 별로 들지 않으면서도
Stratix 10 디바이스의 경우 이전 세대의 고성능 FPGA에 비해 평균 1.6배의 성능 향상을 가져온다. 하이퍼 파이프라이닝은 ALM들
간의 인터커넥트에 여분의 파이프라인 스테이지들(pipeline stages)을 추가하여 디자인이 보다 빠른 클럭 주파수로 실행될 수 있도록
함으로써 긴 배선 지연을 없애준다.
이 역시 인터커넥트 전반에 위치해 있는 하이퍼 레지스터들 덕분에 레지스터 위치를 미세하게 선택할 수 있다. 하이퍼 파이프라이닝도 하이퍼
리타이밍의 경우와 마찬가지로 FPGA의 로직 및 배선 자원들을 추가로 사용하지 않으며 배치 및 배선 작업 후에 이루어진다.
하이퍼 옵티마이제이션
일부 디자인들은 데이터 경로를 하이퍼 리타이밍과 하이퍼 파이프라이닝으로 가속시킨 후에 긴 피드백 루프 및 상태기기와 같은 제어 로직에
의해 제한을 받는다. 보다 고성능을 달성하기 위해서는 이 로직 부분들의 구조를 개혁하여 긴 조합형의 피드백 경로 대신에 기능적으로 동등한 피드
포워드(feed-forward) 또는 사전설정(pre-compute) 경로들을 이용해야 한다. 이 방법은 디자인에 따라서는 좀더 많은 노력이
요구되지만, Stratix 10 디바이스의 경우 이전 세대의 고성능 FPGA에 비해 2배 이상의 성능 향상을 가져온다. 기존의 아키텍처에서는 이
프로세스를 설계 최적화라고 한다. 그러나 HyperFlex 아키텍처에서는 이 프로세스를 하이퍼 옵티마이제이션이라고 부르는데, 이는 하이퍼
레지스터로 인해 하이퍼 리타이밍과 하이퍼 파이프라이닝의 이점들이 피드 포워드 또는 사전설정 경로에 적용되기 때문이다.
하이퍼 어웨어 설계 흐름
알테라는 강력한 일련의 새로운 툴들을 개발하여 Quartus II 설계 소프트웨어에 통합시켰는데, 이 툴들은 시스템 개발자들이
HyperFlex 아키텍처를 충분히 이용하여 개발자의 설계 생산성을 극대화하도록 도와준다. 그림 4는 Quartus II Hyper-Aware의
설계 흐름을 보여준다.
![[그림 4]](img_20150707185055.png)
[그림 4] 하이퍼 어웨어 설계 흐름
패스트 포워드 컴파일
이 새로운 툴은 디자인에서 성능을 제한하는 영역들이 어디인지 확인하고, 성능 향상을 위해 어디에 얼마나 많은 파이프라인을 사용할 수
있는지 알아내며, 중요한 제어경로 상의 병목지대(긴 피드백 루프와 같은)를 강조표시 함으로써 사용자에게 성능 최적화 프로세스를 안내해 준다. 이
툴은 또한 개발자들이 자신들의 기존 디자인을 Stratix 10 디바이스로 구현할 경우 그 성능을 예상함으로써 새로운 HyperFlex
아키텍처를 최적으로 이용할 수 있게 해준다.
하이퍼 리타이머
하이퍼 리타이머 단계는 설계 컴파일 작업의 막바지 무렵에 이루어진다. 이 단계는 배치 및 배선 작업 후에 하이퍼 레지스터를 이용한
최적의 미세 하이퍼 리타이밍으로 성능을 최적화한다. 이 단계는 또한 사용자가 하이퍼 파이프라이닝을 기존의 파이프라이닝보다 훨씬 더 손쉽게 구현할
수 있도록 해준다. 패스트 포워드 컴파일 리포트 기능은 어떤 클럭 도메인들이 파이프라인 스테이지의 이점을 누릴 수 있으며 얼마나 많은 파이프라인
스테이지가 필요한지 확인해 준다. 개발자가 RTL을 수정하고 각 클럭 도메인의 경계 부분들에 미리 정해진 수의 파이프라인 스테이지를 배치한
뒤에는 하이퍼 리타이머가 레지스터들을 클럭 도메인 내의 최적의 위치에 자동 배치함으로써 성능을 극대화한다. 이 자동 배치 기능과 패스트 포워드
컴파일 리포트 기능 덕분에 파이프라이닝은 과거 그 어느 때보다도 쉬워진다.
하이퍼 어웨어 알고리즘
합성과 배치 및 배선 작업 시에 사용되는 하이퍼 어웨어 알고리즘은 툴이 어떤 레지스터들을 ALM으로부터 인터커넥트 배선 내의 하이퍼
레지스터로 옮겨 넣을 수 있는지 예측함으로써 로직 자원을 절약할 수 있도록 해준다.
결론
새로운 HyperFlex 아키텍처와 인텔 14nm Tri-Gate 공정 기술의 조합은 Stratix 10 FPGA와 SoC가 이전에는
상상도 못했던 수준의 성능과 집적도 및 전력 효율성을 프로그래머블 로직 디바이스에 구현할 수 있도록 해준다. Stratix 10 디바이스가
제공하는 특징은 다음과 같다
- 이전 세대의 Stratix V FPGA보다 배가된 코어 성능과 5배 이상 높아진 집적도
- 동일한 성능일 경우 Stratix V FPGA보다 최대 70퍼센트 적어진 소비 전력
- 1 GHz 속도로 동작 가능한 로직, 내장 메모리 및 DSP 블록
- 내장된 콰드코어 64비트 ARM Cortex-A53 하드 프로세서 시스템(SoC 버전)
- 하이퍼 어웨어 설계 흐름
- 입증된 Quartus II 소프트웨어의 지원을 받는 익숙한 FPGA 설계 기법들
[참고문헌]
- 1. Global Internet Capacity Reaches 77 Tbps Despite Slowdown
www.telegeography.com/press/press-releases/2012/09/06/global-internetcapacity-reaches-77-tbps-despite-slowdown/index.html - Gartner Says the Internet of Things Installed Base Will Grow to 26 Billion Units by 2020
www.gartner.com/newsroom/id/2636073 - 400 Gbps Ethernet Study Group
www.ieee802.org/3/400GSG/ - Cisco Visual Networking Index: Forecast and Methodology, 2012-2017
www.cisco.com/c/en/us/solutions/collateral/service-provider/ip-ngn-ip-nextgeneration-network/white_paper_c11-481360.html - Satellite Backhaul & Trunking Are Capacity Driven Markets
www.nsr.com/news-resources/the-bottom-line/satellite-backhaul-trunking-arecapacity-driven-markets/ - Cisco Visual Networking Index (VNI) Global Mobile Data Traffic Forecast Update
www.ciscoknowledgenetwork.com/files/222_03-27-2012-CKN_Cisco_Mobile-VNI-Forecast_2012_CKN_Deck.pdf - Global Census Shows Datacentre Power Demand Grew 63% in 2012
www.computerweekly.com/news/2240164589/Datacentre-power-demand-grew-63-in-2012-Global-datacentre-census - My New Study of Data Center Electricity
www.koomey.com/post/8323374335
보다 상세한 내용
새로운 HyperFlex 아키텍처와 인텔의 14nm Tri-Gate 기술, Stratix 10 FPGA 및 SoC에 대한 보다 상세한 내용
- White Paper: The Breakthrough Advantage for FPGAs with Tri-Gate Technology
www.altera.com/literature/wp/wp-01201-fpga-tri-gate-technology.pdf - Stratix 10 FPGAs and SoCs: Delivering the Unimaginable
www.altera.com/devices/fpga/stratix-fpgas/stratix10/stx10-index.jsp
Copyright 2015. (주)채널5코리아 Corporation. All rights reserved.
출처: http://www.e4ds.com/sub_view.asp?ch=17&t=1&idx=2384 영어원문: https://www.altera.com/en_US/pdfs/literature/wp/wp-01220-hyperflex-architecture-fpga-socs.pdf
![]()
![]() Send to a colleague |
Send to a colleague | ![]() Print this document
Print this document